Most of the time in machine learning is spent coming up with clever ways to estimate underlying probability distributions from which
the observed samples have been drawn by chance, or waiting for said clever ways to rack up a sizable computing bill. But what if we have a lot of data?
In such cases, we often use histograms to get a compressed representation.
Similarly, the underlying (parametric) distribution can be discretized for faster computations, with an often negligible effect on accuracy.
Such formulation can arise if the parametric model itself is defined as a mixture of (binned) empirical distributions
(as in this real-world example).
How do we find the maximum likelihood estimate (MLE) of the distribution parameters in this binned world?
My intuition suggested that MLE should be equivalent to minimizing the KL divergence
between the emprical and the model distributions. Nontheless, I felt that it was worth going through
a simple derivation to remove any doubt.
In which we struggle to come up with acronyms, and end up with DQQRNs
Least squares regression is taught early on in every science course. The mean squared error (MSE) arises naturally from minimizing the negative-log-likelihood under an assumed Gaussian distribution of outcomes - a special case of the Gaussian mixture density with $m=1$ components (and $\sigma=\textrm{const}$). Less frequently, however, engineers, statisticians, and other like-minded individuals need regression models less sensitive to outlier - and replace MSE with the mean absolute error (MAE).
Statistically speaking, minimizing the MSE allows us to learn the (conditional) mean of our data, while minimizing the MAE results in the median. The median estimate is empirical and does not rely on assumptions about the underlying distribution. The median is a special quantile - can we generalize our MAE loss function to learn other quantiles in a similar way?
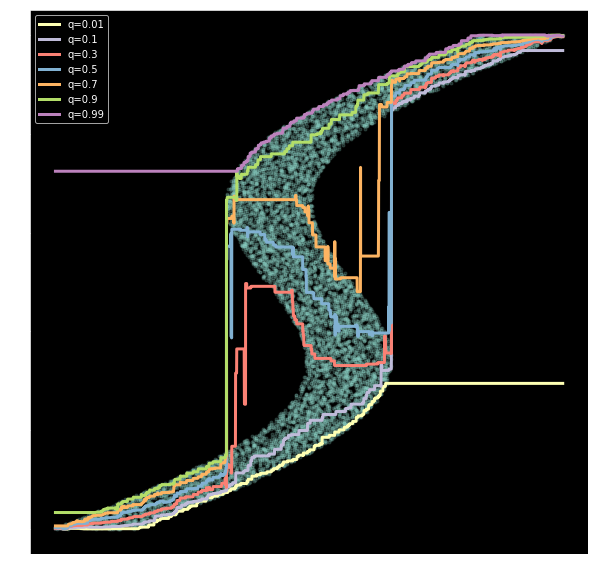
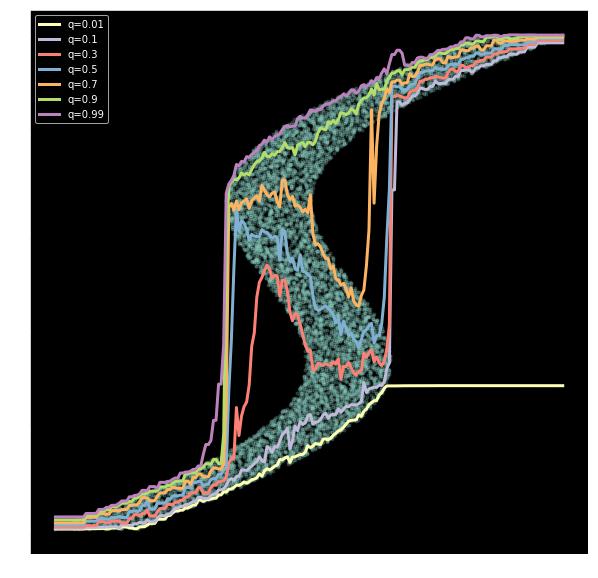
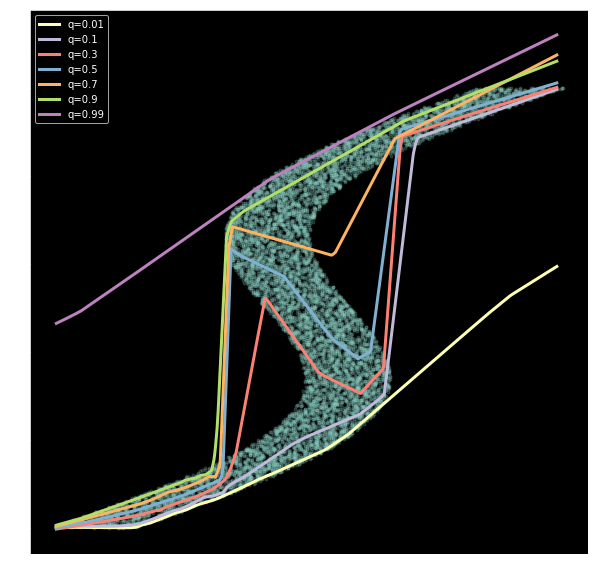
scikit-learn GBR with quantile loss
Catboost with quantile loss
NN with quantile loss (one model per quantile)
In this post, we introduce the Quantile Loss and use Deep Quantile Regression to get an alternative view on the uncertainty in the target variable - and also propose
some (to my knowledge) new approaches as an unfinished experiment for the curious reader.
In which we (attempt to) speed up sampling from a mixture density model
In Part 1 of this series of posts, we trained a Mixture Density
Network to capture a heteroscedastic
conditional probability distribution.
After predicting the parameters $(w_{ij}, \mu_{ij}, \sigma_{ij})$ of the $m$ mixture components, we would like to
generate some - and in some cases many - samples from the learned distribution.
A fully vectorized implementation for the problem at hand required some thought, so I decided
to write it up for future reference.